Como indicaba en la entrada la anterior entrada Almacenamiento en Kubernetes: problema abierto, el problema de proporcionar almacenamiento persistente para las aplicaciones desplegadas en Kubernetes sigue sin tener una solución general.
En este artículo comento una solución particular al problema del almacenamiento basada en el uso de un contenedor sidecar.
Opciones disponibles
En esta fase inicial de aprendizaje de Kubernetes el uso de almacenamiento en la nube (AWS, GCE, etc) no es una opción debido a los costes.
Las opciones como Gluster o Ceph requieren hardware adicional (como mínimo, dos nuevas máquinas). El coste de incorporar dos nuevas RPi al clúster no sería excesivo, sólo Ceph parece que está trabajando en dar soporte a ARM mientras que para Gluster no he encontrado nada (a parte de una entrada en su blog del 2012).
En cuanto a NFS, requeriría “sólo” una máquina adicional, pero no he encontrado demasiada información al respecto (en cuanto a cómo usar NFS con Kubernetes). Se asume un conocimiento de Linux y de cómo funciona NFS que debería obtener, lo que supone invertir tiempo en un concepto interesante, pero marginal en cuanto a Kubernetes.
Mi intención es encontrar una solución lo más relacionada con Kubernetes como sea posible. En este sentido he estado revisando Minio, que proporciona una API 100% compatible con el almacenamiento de Amazon S3. De esta forma, es posible usar tanto una solución local (con Minio) como una en el cloud (usando S3).
El problema es que la aplicación debería usar el cliente de Minio para poder acceder al almacenamiento. Esto no es posible sin modificar la aplicación.
En los repositorios de Minio en Github he encontrado el proyecto MinioFS cuya descripción es justo lo que necesito:
MinFS is a fuse driver for Amazon S3 compatible object storage server. MinFS lets you mount a remote bucket (from a S3 compatible object store), as if it were a local directory. This allows you to read and write from the remote bucket just by operating on the local mount directory.
MinFS helps legacy applications use modern object stores with minimal config changes. MinFS uses BoltDB for caching and saving metadata, list of files, permissions, owners etc.
Desgraciadamente, no tiene soporte -todavía- para ARM (issue #26 ARM support for MinFS).
Una opción viable
Dándole vueltas a la posibilidad de usar Minio, he decidido cambiar el problema: si la aplicación no puede escribir sobre el almacenamiento de Minio, que sea el propio Minio el que obtenga la información de la aplicación. La solución que me ha venido a la cabeza tiene que ver con el pattern del contenedor sidecar: The Distributed System ToolKit: Patterns for Composite Containers.
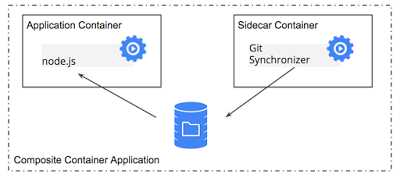
Ejemplo 1 Contenedor sidecar
Buscando en Google hace unos días encontré el artículo Minio, simple storage for your cluster donde se exponía la idea del uso de un contenedor sidecar para realizar las tareas de replicado de la información del pod, aunque la solución final me pareció, en su momento, demasiado complicada.
El contenedor sidecar
El contenedor sidecar reside junto al contenedor de la aplicación y realiza una función auxiliar a la del contenedor principal. En mi caso, el contenedor sidecar contendría el cliente de Minio mc.
El contenedor principal lee y escribe sobre un volumen local (en el pod). El contenedor sidecar se encarga de copiar ficheros del pod hacia el exterior (hacia el bucket definido en el servidor de Minio).

Al tratarse de volúmenes locales al pod, el scheduler los crea junto con el pod (a partir de la definición en el deployment). Kubernetes los crea automáticamente, sin ninguna dependencia de los plugins de almacenamiento ni de si permiten provisionamiento dinámico o no. Así podemos escalar la aplicación sin necesidad de provisionar nuevos PersistentVolumes.
Cuando se crea un nuevo pod, el volumen inicialmente está vacío, por lo que hay que “descargar” los ficheros desde el almacenamiento remoto. Esta tarea de configuración inicial es justo el objetivo de los contenedores init.
Una vez que ha finalizado la copia inicial de la información desde el bucket remoto al volumen local, se lanzan los contenedores de la aplicación y el sidecar, en paralelo.
A partir de la “puesta en marcha” del pod (cuando el contenedor init finaliza con éxito), el contenedor sidecar se encarga de ir sincronizando el contenido del volumen con el del bucket remoto.
El servidor de Minio se puede desplegar sobre Docker como un contenedor.

Para garantizar que en todo momento tenemos un servidor de Minio capaz de atender las peticiones desde cualquiera de los clientes, podemos desplegarlo en forma deployment. Para evitar que el scheduler lo planifique en un nodo diferente al que tiene montado, tendremos que definir afinidad con el nodo en el que se encuentra.

Aunque esta última variante sólo proporciona balanceo para el servidor de Minio, el almacenamiento no está replicado y un fallo del hardware subyacente nos deja sin datos.
Con esta configuración es posible proporcionar almacenamiento local de un nodo como almacenamiento “cloud local”, es decir, desde cualquier nodo del clúster, externo a la aplicación. El servidor de Minio actúa como proxy del almacenamiento local del nodo. Este contenedor sidecar puede usarse con cualquier aplicación sin necesidad de modificación, ya que el cliente de Minio es el que se relaciona con el almacenamiento externo (la aplicación trabaja sobre el almacenamiento local en el pod). Cuando el pod se planifica en cualquier otro nodo del clúster, el contenedor init recupera la información desde el servidor antes de la creación de los contenedores de la aplicación y el cliente de Minio. Una vez inicializado, el pod opera con normalidad, la aplicación leyendo y escribiendo ficheros en el volumen local del pod y el cliente Minio sincronizándolos contra el bucket remoto en el servidor de Minio.
El siguiente gif animado describe este proceso:
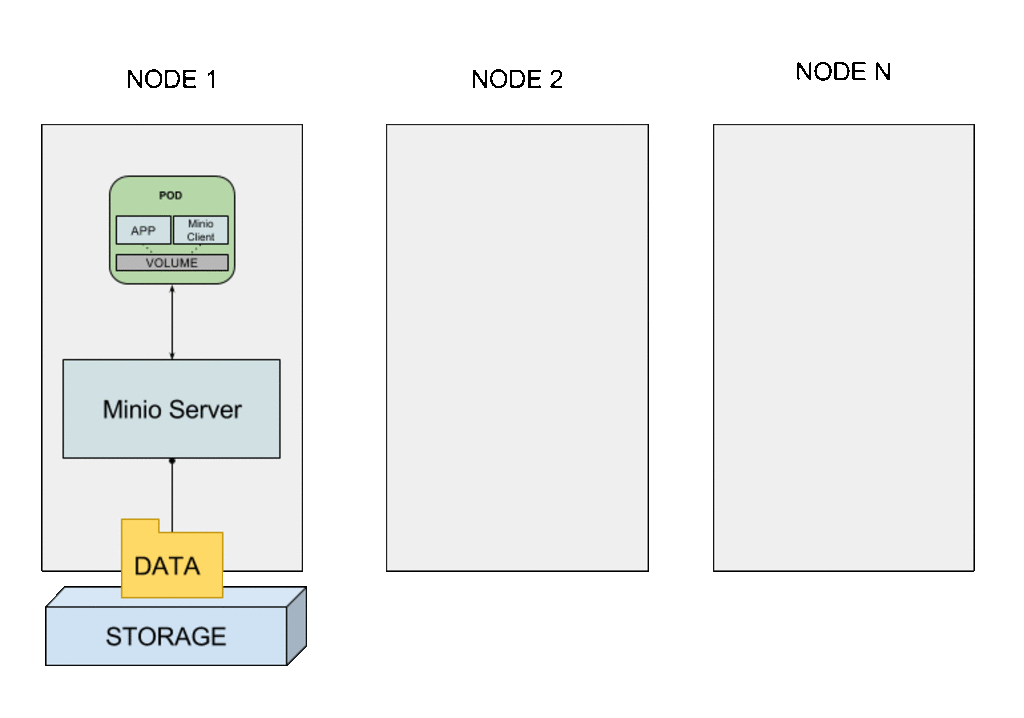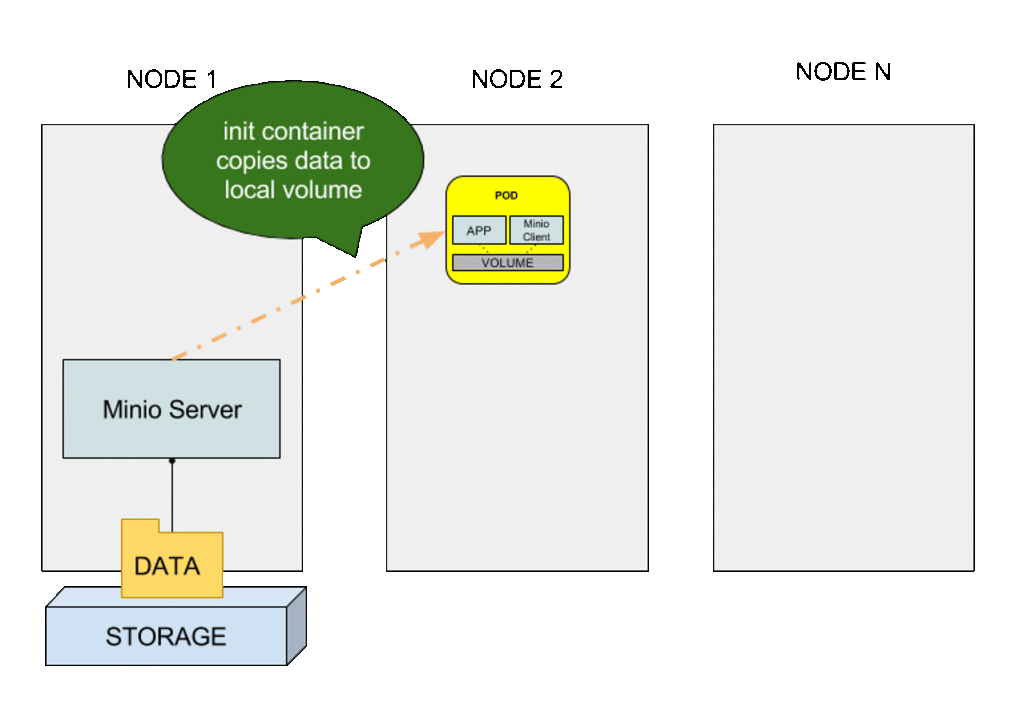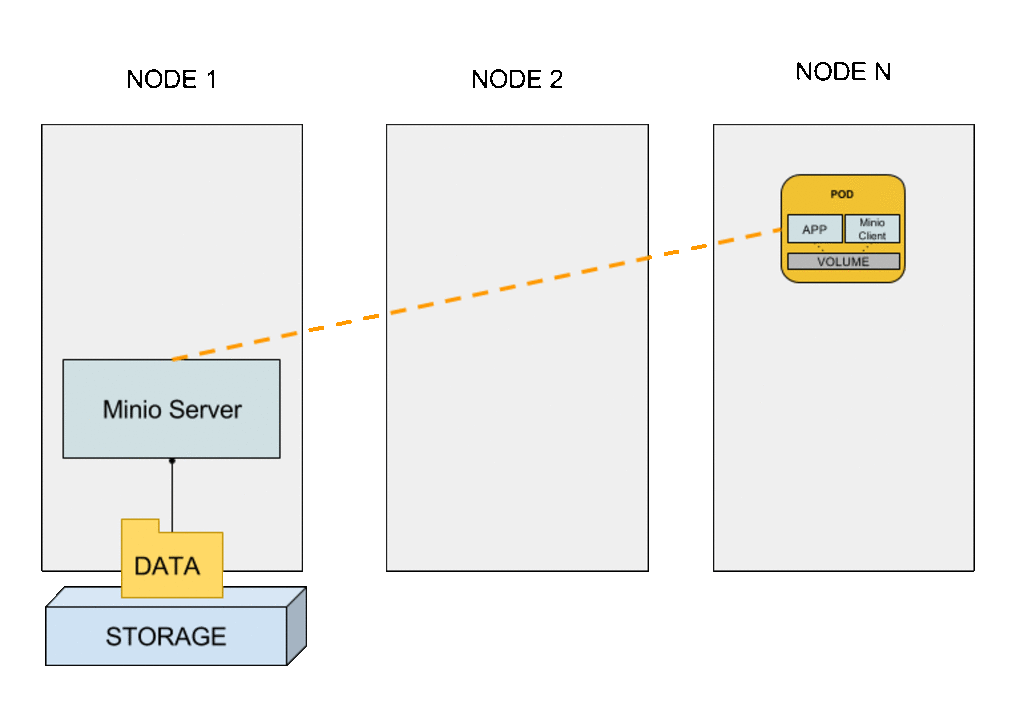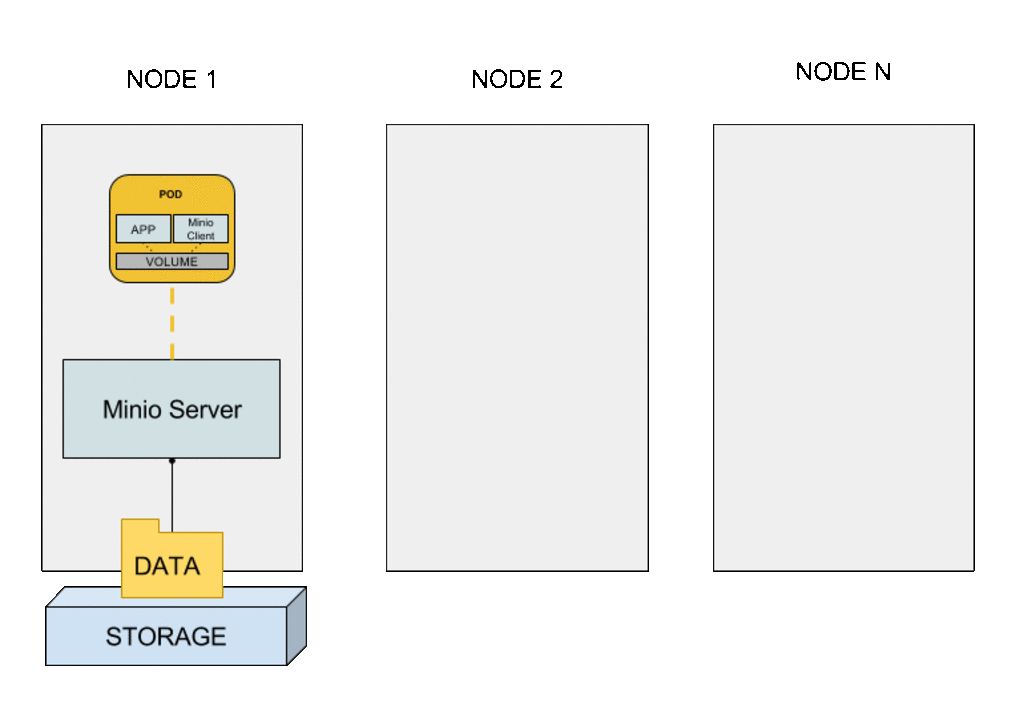
Pod keeps persistent storage across nodes
El siguiente paso es probar la viabilidad de esta idea a la práctica.